可能大多数人都不知道 Fiber 是什么。如果你不知道,不必担心,因为我会从最基本的开始。解释它是什么,以及它是如何工作的。
Fiber 的作用
这是一个 React app 的例子:

左边是现在的 React 的效果,右边是使用了 Fiber 的 React 的效果。这是一个玩具性质的应用,它本身不是很有用处,但却可以很好地替代现实中的 app。我过会儿会解释原因。
很明显,Fiber 为像上图这样的复杂 React 应用提升了用户感知的性能和响应。
Fiber 是什么?
Fiber 是 React 新的协调算法(reconciliation algorithm)。
术语“协调算法”对一些人来说可能比较陌生,我来解释一下它的出处。
当 React 刚刚问世,杀手锏是虚拟 DOM,因为它使编写用户界面简单了许多。比起必须告诉浏览器从前一版本的 app 到后一版本该如何做,我们可以直接告诉 React,下一版本看起来应该是什么样子的,React 就会处理中间的事。事实证明,这个不仅在处理 Dom 的时候有用,在处理其他方面的时候也很有用,比如硬件、虚拟现实、原生应用。
If we actually wanted to be able to address these use cases, though, I was going to have to factor out the part of React that figured out the changes from the previous version graph to the next version from the part that actually manipulated the Dom to get it there.(我实在不知道该如何对这句话断句,请路过的大大指教 QAQ)

这张图介绍了协调器和渲染器的正式区别。渲染器是可插拔的,所以你可以使用来自外部、来自社区其他地方的渲染器,以面向除 DOM 以外的其他主机平台。
但核心的协调算法只有一个,所以 Fiber 如此重要。过去几年,React 核心团队全面重写了这个核心特性——React 的杀手锏,其结果就是 Fiber 协调器。
产生卡顿和不响应的原因
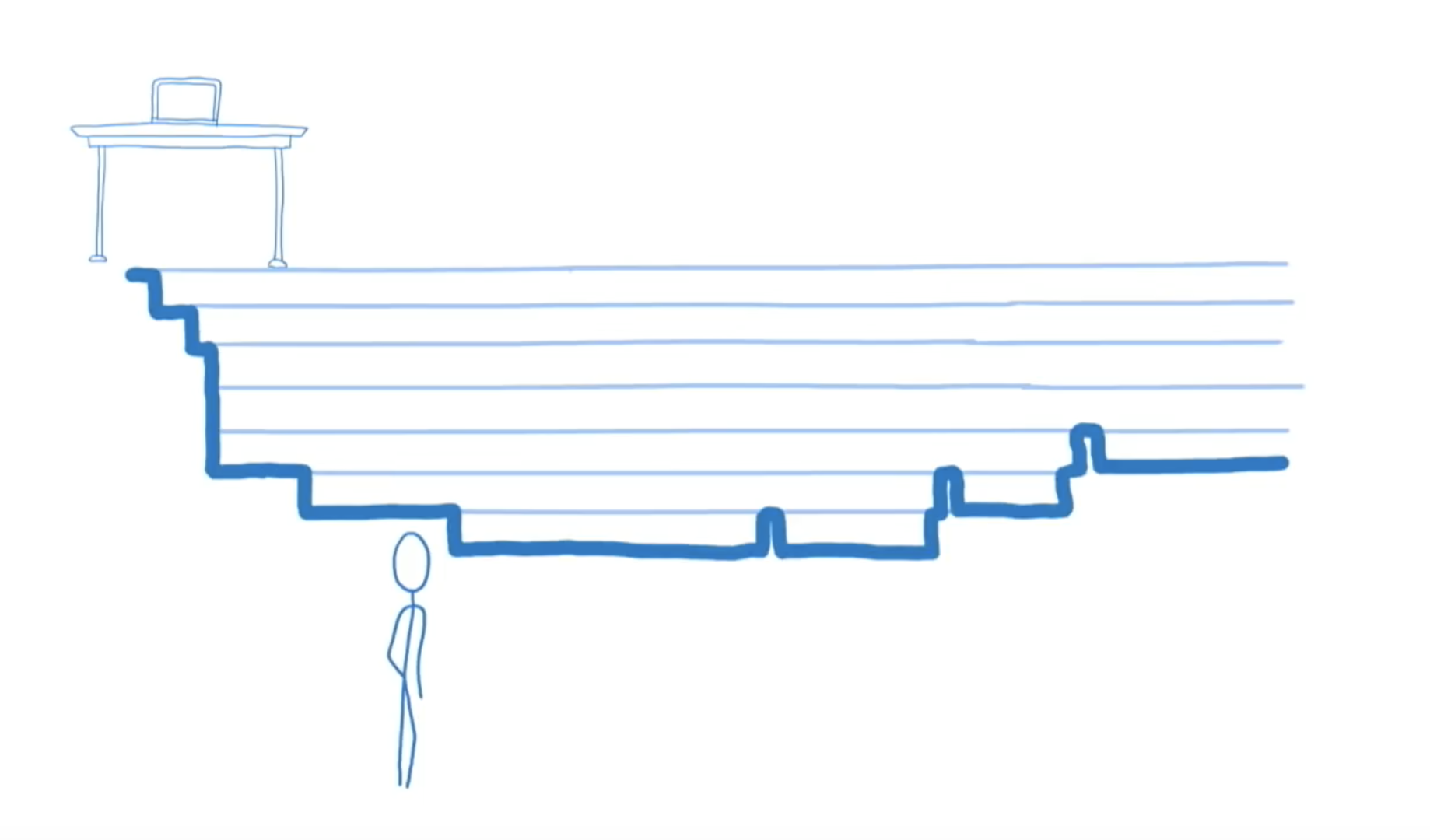
Fiber 调解器为什么能把左边这么卡顿的运动变得像右边这样流畅呢?让我们先看看这个 demo 是怎么回事。
在这个 demo 中有两种不同的更新在同时进行,一种是使三角形变宽变窄,另一种是到每一个点里改变数字。这对于实际生活中的 app 是一个很好的替代,因为它使两种更新之间的相互作用可视化。更新是存在优先级高低的区别的。举例来说,当你在打字的时候,你需要立即得到反馈,这是高优先级的更新。当你从服务器取到值,需要更新一个评论的赞的数量,这是低优先级的更新。
这个 demo 展示了在高优先级更新和低优先级更新同时进行的时候会发生什么。
那么,让我们看看这个 demo。在最顶层有一个三角形:
接着有更多的三角形:

一直到最底层,会有一个点。
这些更新会涉及到这棵树上不同的部分。变宽变窄的更新只涉及到顶层的三角形,所以计算量不是很大,但是发生得很频繁,每 16ms 就要更新一次,这样才能给用户流畅的体验。
与此同时,另一种更新的计算量却很大,因为它涉及到这棵树上的每一个实例。但这种更新一秒只发生一次,因此如果它不是立刻发生的,比如晚个一二百毫秒,你可能并不会注意到。
让我们按时间顺序来看。为了让外层的运动看起来流畅,我们需要每秒 60 帧,即 16ms 每帧。你可能觉得为了达到这个目的,需要 React 本身更快。但问题不在于外层的更新不能在 16ms 内完成,毕竟它只接触一个实例。实际上,它卡顿的原因是被后面更大的更新卡住了。而在这些更大更新上花费的时间,实际上大多都是花在了 render 函数和其他函数之类的用户代码上,而不是 React 本身。所以让 React 本身更快不能快到解决这个问题。
但有一种方法解决这个问题,就是使不同的更新更好地配合在一起。当然,不单是 React 更新需要配合得更好,浏览器来的更新(比如 CSS 动画、浏览器 resize)也是一样,这些也会被更大的更新卡在后面。这是浏览器的工作方式导致的。
当你在建立一个网站时,你的代码就像是这个网站的项目领导。很不幸,只有一个雇员工作来建立这个网站,他就是主线程。所以,主线程有点像全栈工程师,他做 DOM、JavaScript、layout……所有事。所以,只要正在处理 JavaScript 更新,它就不能做其他事,不能做 layout 之类。
Fiber 是如何解决问题的
那么,当你使用 React 时,它是如何缓解这个问题的?它知道如何更好地和主线程一起工作吗?
React 有点像一个技术领导,它很清楚主线程是如何工作的。所以,它能够使主线程处理工作更高效,它可以依靠最小化和批量处理 DOM 变化来指导主线程工作。
Fiber 做的基本就是教技术领导(React)一些基本的项目管理技巧,比如如何切分工作,如何划分工作优先级。同时,它还能让技术领导持续追踪时间已经过去了多久。那么,这些新技能是如何参与进来的呢?又是如何改变协调器的工作方式的呢?让我们先看看目前的协调器是如何工作的吧。
栈调解器的工作过程
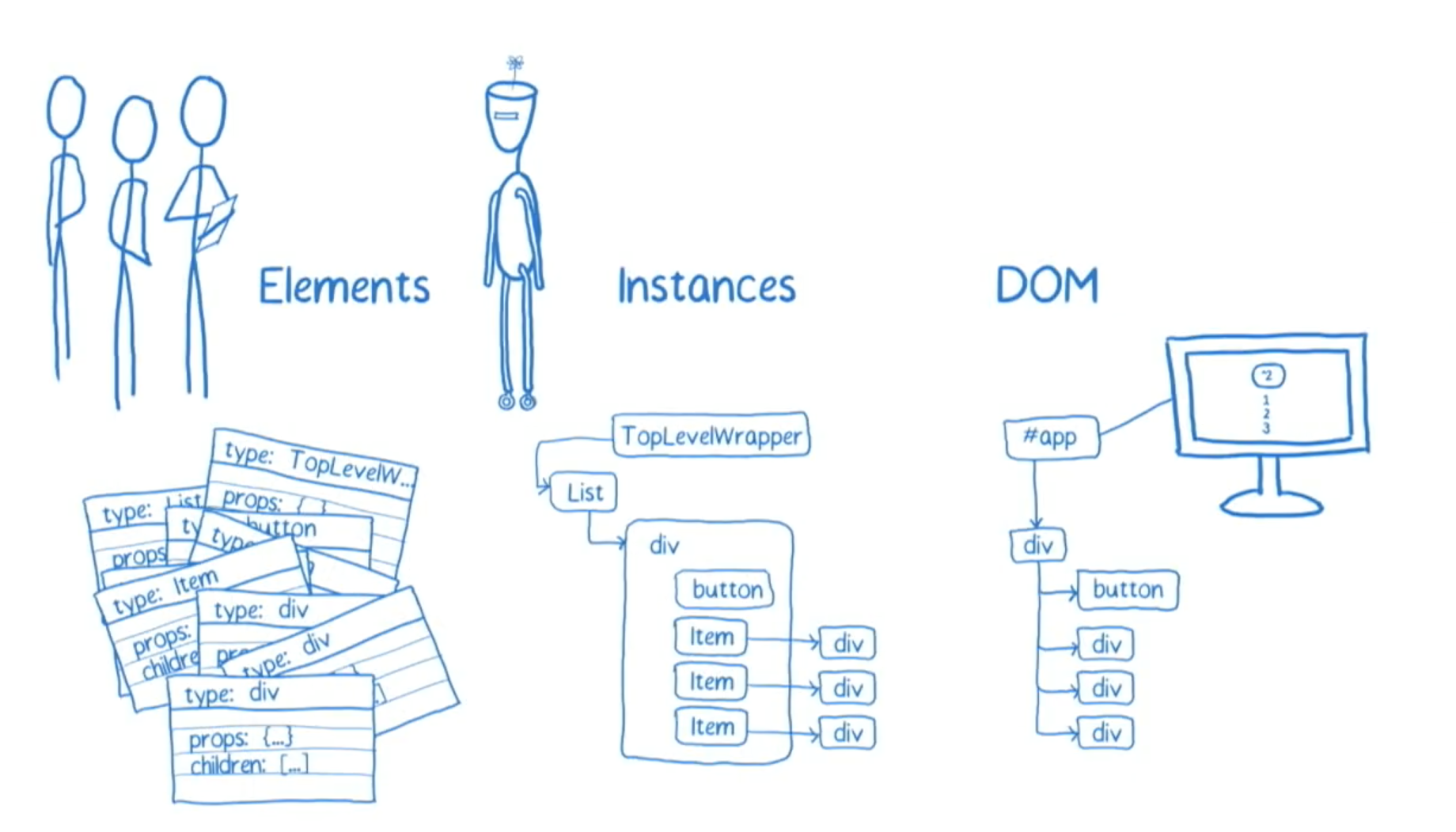
先看看上面的图。在左边,你可以看到元素(element),这是你的组件在 render 中返回并告诉 React 应该构建的东西。在中间的是实例(instance),React 创建实例,并依靠实例来搞清楚上一个 state 是什么,下一个 state 是什么,React 需要造成什么改变。接着,React 使用 DOM 节点来真正告诉浏览器它需要做什么的。
如果使用目前的调解器,以上是被一层一层构建的。也就是说,React 会创建 element,接着 instance,接着 DOM 节点,也可能会更新 instance 或者 DOM 节点。为此,它递归调用对组件的 mount 或者 update,直到到达树的底层。
因此,如果你在你的浏览器开发工具中记录了这个过程的 timeline,你会看到这个过程的图形表现。你会看到一个拥有所有递归调用的栈,它会变得越来越深。这其实告诉我们问题出在哪儿,因为主线程卡在了调用栈底部的所有调用之下。如果你需要主线程能够上来检查其他工作,看看是否需要做其他事,你得解决掉这个情况。
Fiber 做了这件事。
Fiber 调解器的工作过程

Fiber 使主线程能够只计算一小部分树,然后回到上面,检查是否有其他工作要做。它通过一种叫“fiber”的数据结构来记录它在这棵树中的位置的,这也是 Fiber 调解器名字的来源。
之前的调解器没有名字,我们就先叫它“栈调解器”,因为它通过栈来持续追踪同样的事。
fiber 只是普通的 JavaScript object,它和 instance 一一对应,为 instance 管理工作。fiber 使用属性“stateNode”来记录当前追踪的是哪一个实例,它同时记录自己和树中其他 fiber 的关系。
我们可以举例来说明 fiber 工作的整个过程。
协调 React 更新与普通 JavaScript 更新的例子

上图是一个列表,其中含有一个按钮。点击按钮,它会将列表中的数字平方。这个例子中包含了一个 List 组件,对 List 组件调用 render,它会返回一个数组。
接着,让我们来构建对应的树:

在这棵树中,第一个 fiber 是“HostRoot”,它实际上是和你注入 React app 的那个 DOM 中的 container 是相对应的。它的第一个子 fiber 是 List。从 HostRoot 到 List 的关系被称为“child”,从 List 到 HostRoot 的关系被称为“return”。Button 相对于 List 同样有 child 和 return 的关系。但是第一个 Item 没有从 List 到 Item 的 child 关系,而是对 button 有从 button 到 Item 的 sibling 关系。所有的兄弟节点都会指向它们的下一个兄弟节点,这就是 React 遍历树的一层的方法。

上图就是每一个 fiber 记录的关系,包括 child、return 和 sibling。除此之外,fiber 还记录了一些其他的属性。让我们用上面的例子来展示 fiber 工作的整个过程。但在此之前,我们要让这个例子变得更有趣一点:

让我们在上例的右上角增加一个按钮,半路用户会点击这个按钮,使得组件的字号变大。这个操作与 React 无关,只是一次普通的 JavaScript 更新。它会要求主线程做 layout 方面的计算。
在这个例子中,我们应该如何构建 fiber 树呢?

在开始更新之前,我们已经有一棵当前的 fiber 树了,这是在初始化渲染的时候被构建的。同时,React 还会构建一个 work-in-progress 树。需要 work-in-progress 树的原因是,在计算树上的更新时,我们不想真正改变 DOM。这一点和栈调解器不一样,栈调解器工作的方式是,在其沿着树行走并改变实例的时候,它也改变了相应的 DOM 节点。
举例来说,当我们在实例中的数字从 2 改成 4 的时候,实例将会把 DOM 节点中的数字从 2 改为 4。这个过程是在下面那个从 3 到 9 的实例计算之前的。
如果你把所有的事放在同一时间做,也就是说,整个事都是同步的,那么这个过程没什么问题。但是,如果你需要打断这个过程,你需要在 2 到 4 和 3 到 9 的更新之间休息一下,那么,浏览器就会 paint,layout,把数字从 2 变成 4,但是它不知道也需要把数字 3 变成 9。这样,最终,你的界面渲染出的结果就是不正确的。
为了避免这个问题,fiber 加上了阶段(phases)的概念。
阶段一,是 render/reconciliation 阶段。在这个阶段,React 会建立一棵 fiber 树,一棵 work-in-progress 树,然后把所有改变整理为一个列表,但并不会真正的做出更新。只有在阶段二,commit 阶段,才会真的把这个改变更新到 DOM 上。
阶段一是可以被打断的。在这个阶段,React 可能会放开主线程,让它去做别的工作。但第二阶段不能被打断。这些提交必须一次性发生,否则你的界面渲染会出错(比如上个例子中,只把 2 更新成了 4,没有把 3 也更新成 9)。所以,在第一阶段,我们的任务是是建立 work-in-progress 树并找出其中的变化。
让我们来做一次更新,看看 work-in-progress 树是如何构建的。
点击平方按钮,调用 setState。当 setState 被调用,React 会把这个更新添加到更新队列中。接下来,React 会安排工作,目的是把这些更新落实。当 React 得知 setState 被调用时,它不需要马上做这个工作,因为 setState 不是同步的,晚点发生也没关系。React 可以安排其发生的时机。
为了安排工作,React 使用了一个函数,叫做 requestIdleCallback。React 调用这个方法就相当于是在对主线程说,让我知道你什么时候有些空闲的时间,我们再来做这个工作。对浏览器来说,如果它不支持 requestIdleCallback,React 会自行 polyfill。
所以,当一旦主线程完成了它的工作,有空余的时间,它会回到 React 这里,且它知道它可以抽出多长时间。可能是十几毫秒,如果在不久的将来没有帧调度,也可能是50毫秒的时间。
主线程回来了,我们开始建立 work-in-progress 树。我们靠一个叫 work loop 的函数来填充树。work loop 让 React 可以先到树下面去,做一些计算,接着回到上面让主线程能够做其他它需要做的工作。
为了做到这个,work loop 需要记录两件事,一个是接下来它需要做的工作,也就是下一个工作单元(the next unit of work),另一个是它可以占用主线程的时间还剩下多少。

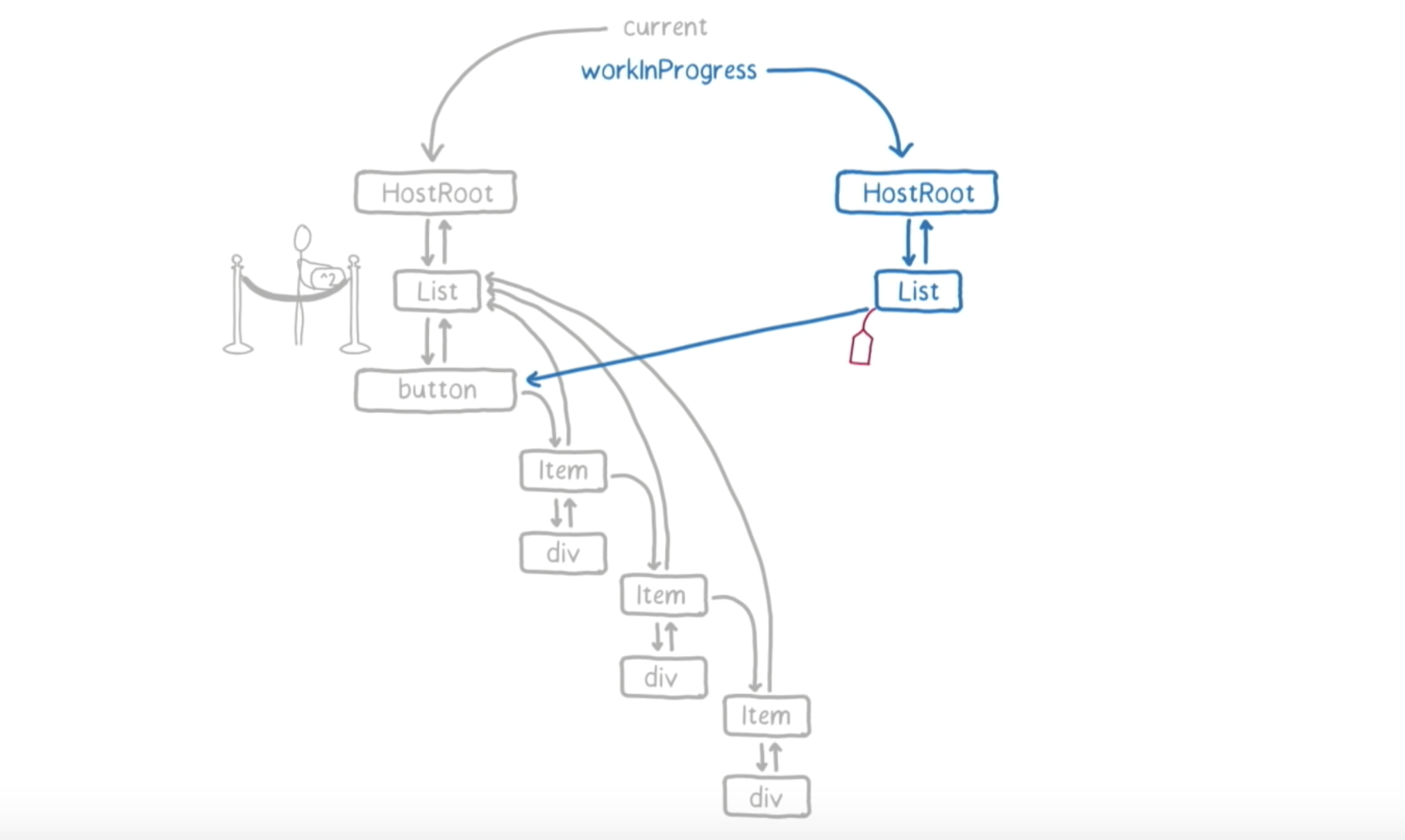
因为有剩余时间,接下来,React 和主线程要开始工作了。首先,从 HostRoot 开始。只需要把当前版本的值克隆到 work-in-progress 树。
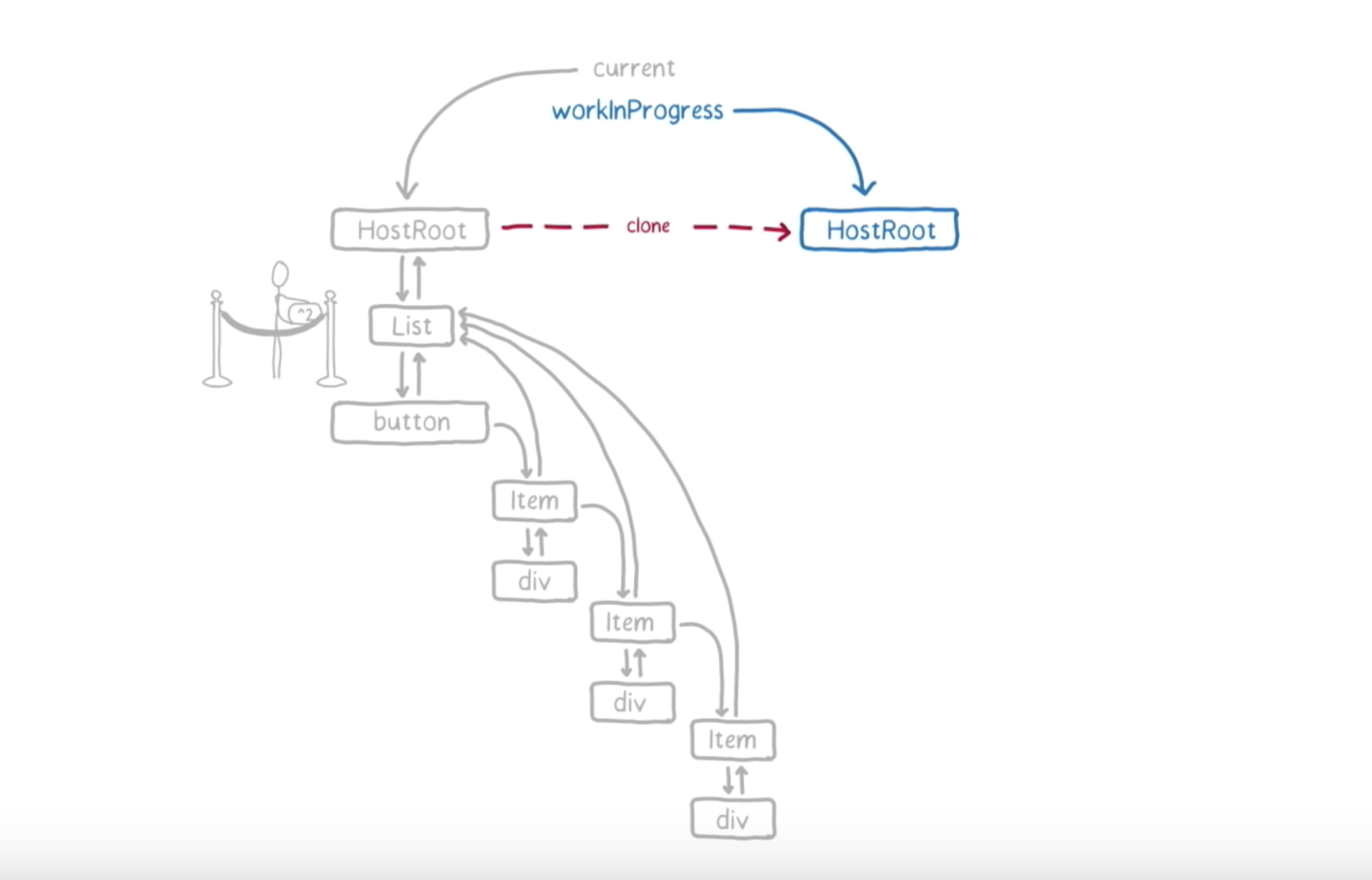
值中包含了一个指向 HostRoot 的 child 的指针,也就是 List。因为 List 没有更新,我们就只需要把 List 克隆到 work-in-progress 树。
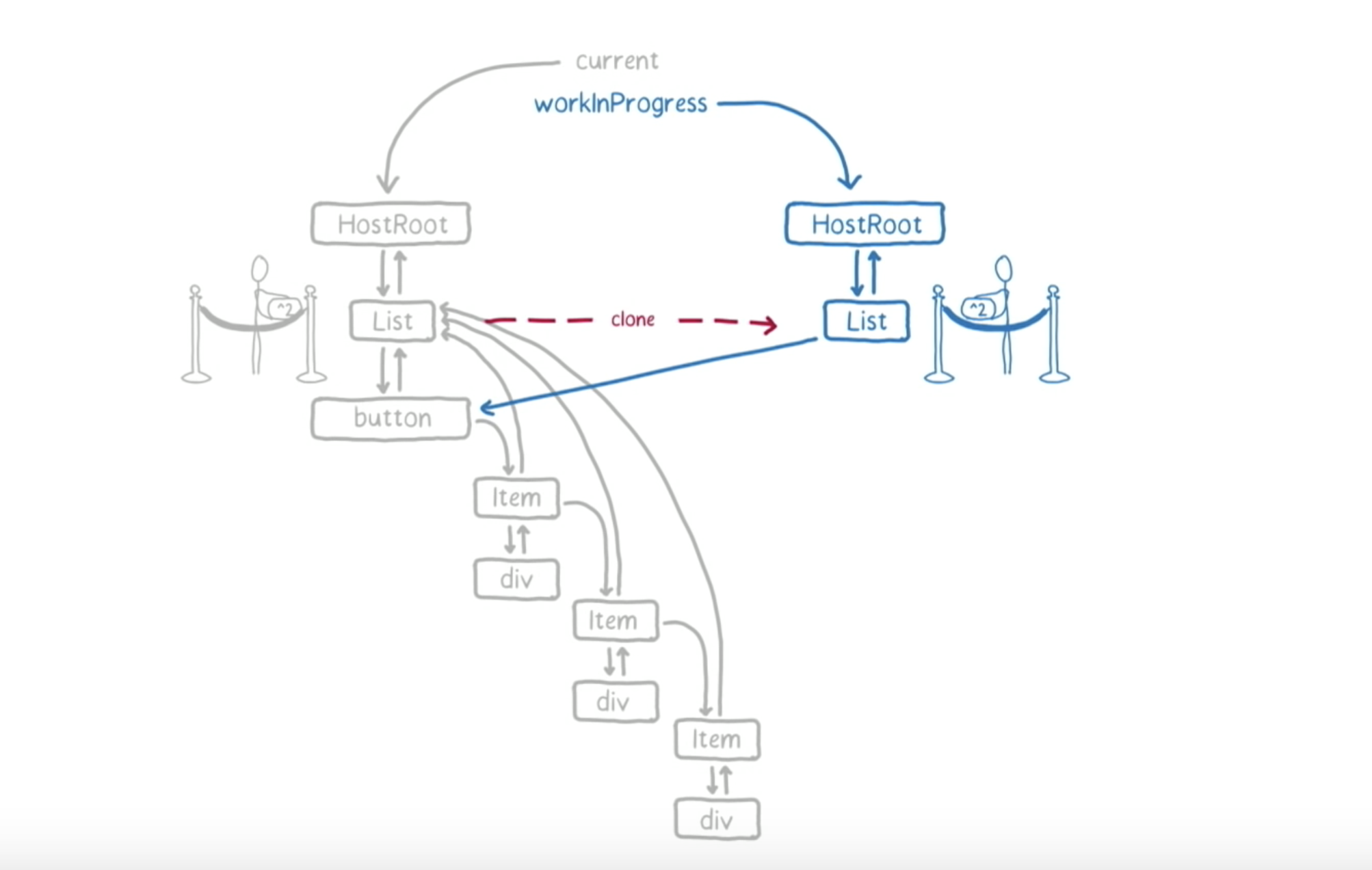
因为 List 有一个更新队列,因此,同时也会克隆这个更新队列。
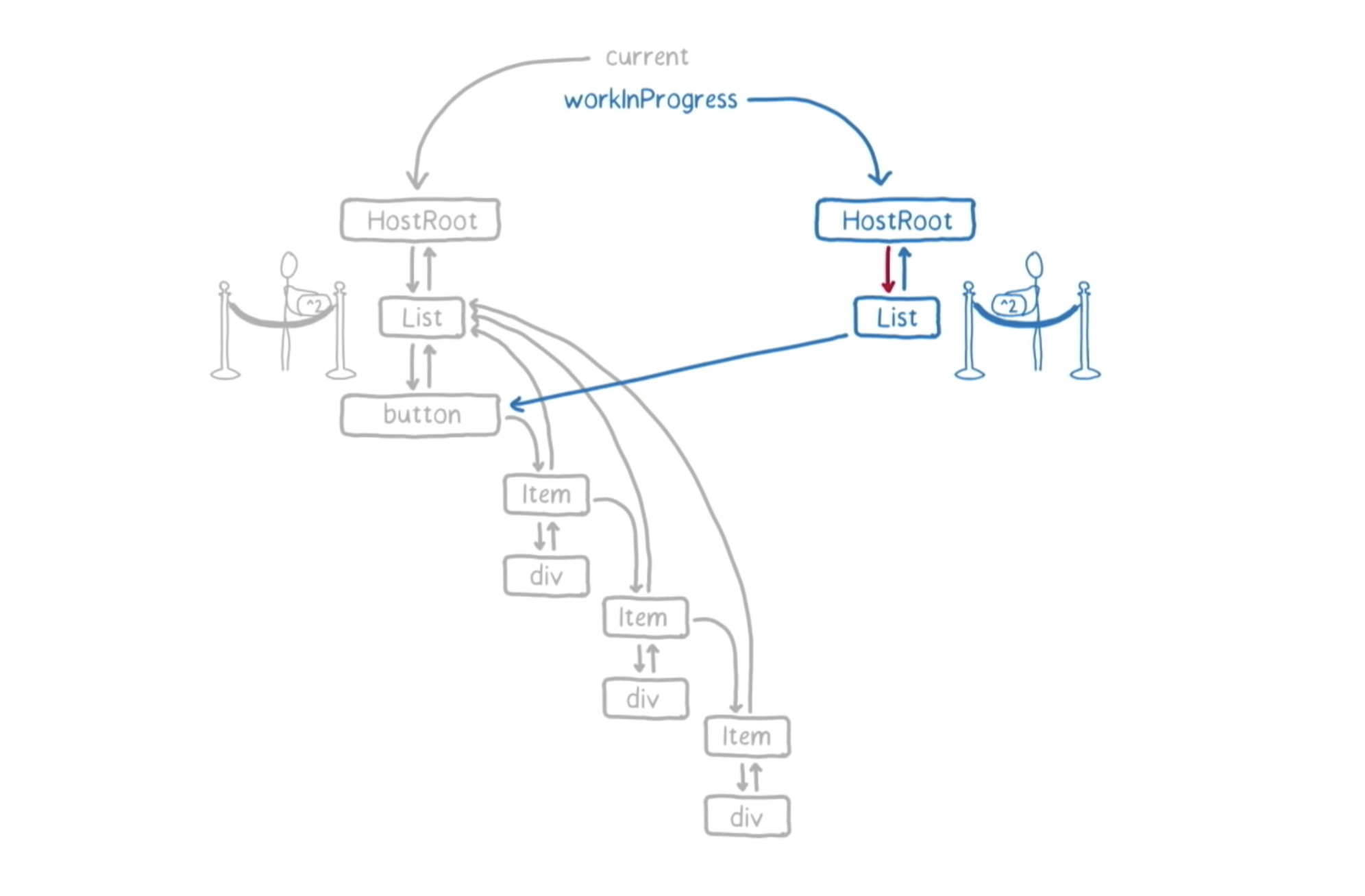
这样,List fiber 就会被作为下一个工作单元 return。接着,React 会回来看一下它的 deadline 是否截止了。
因为我们还有剩余的时间,React 会回来,然后开始处理 List。List 确实有一个更新队列,也就是说,它有 React 需要处理的更新。于是,React 开始处理这些更新。
被传入 setState 的函数被称为更新函数(updater function)。
1 | this.setState((state, props) => { |
你之前可能没怎么见过更新函数。虽然 React 支持更新函数已经好几年了,但大家通常还是只会给 setState 传入 object。但是,在使用了 Fiber 调解器之后,你真的需要开始使用更新函数,并且,object 的形式甚至有可能在什么时候被移除掉。
调用更新函数会返回给我们新的 state,这样,更新队列就被处理完毕了。
这样,这个 fiber 需要被标记,会有一个 tag 打在上面,因为它需要更新 DOM 树。
再向下移动,我们要继续处理这棵树,就需要知道 List 的子节点。因此,React 会把 props 和 state 设置到 List 实例上,然后调用 render。这样,我们就得到了一个 render 返回的 element 数组。React 遍历这个 element 数组,看数组中的 element 和之前是否是一样的,是否能够被复用。
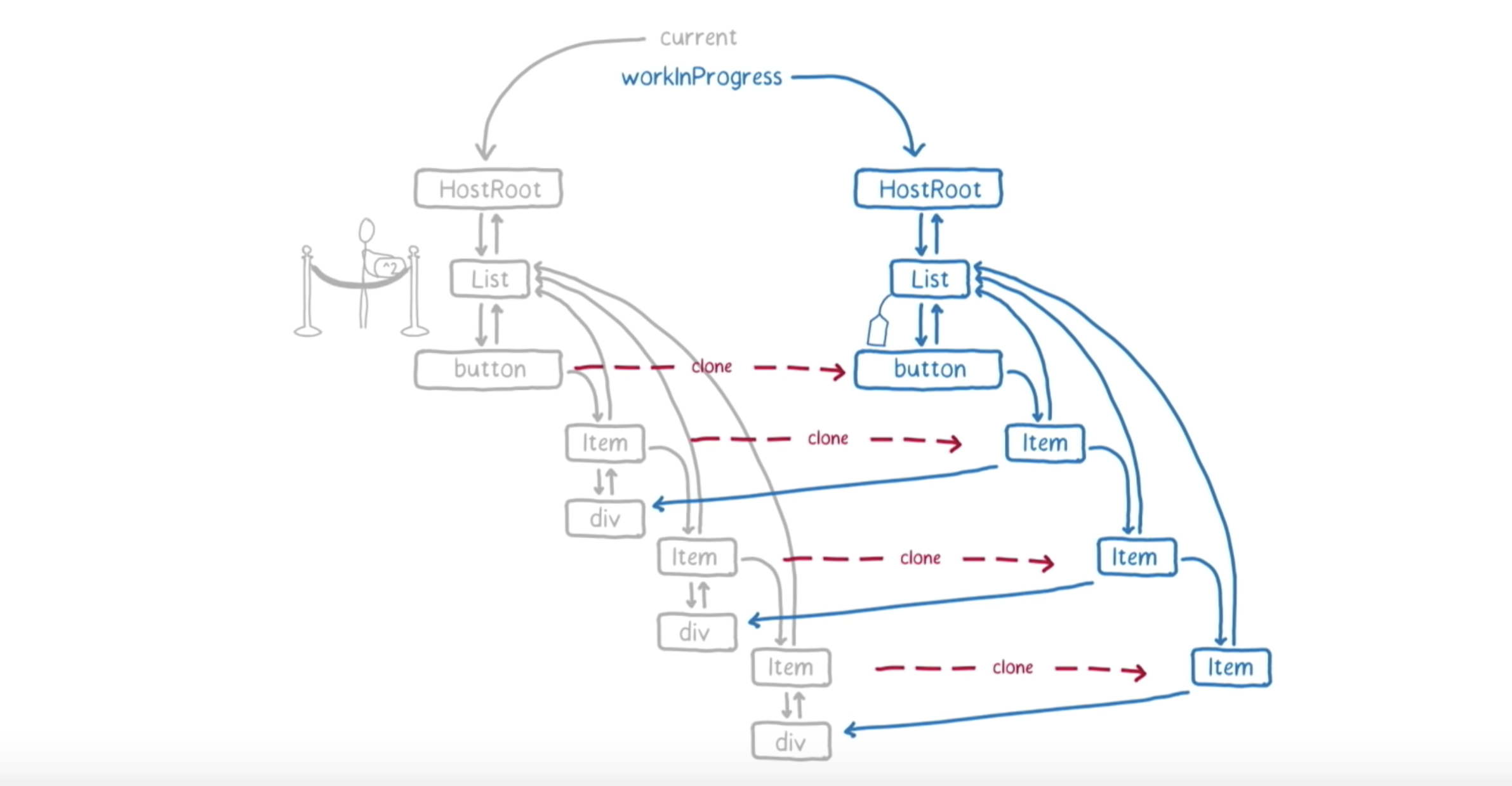
在我们的例子中,elements 都是可以被复用的,所以就直接克隆一下。
接下来,return List 中的第一个 child,即 button,作为下一个工作单元。这时候,React 会回到上面查看一下 deadline。

这时候,假设用户点击了右上角的按钮,使字体放大。这会向主线程需要处理的队列中添加回调。但不会马上被处理。因为 React 仍旧有时间(没有到 deadline)。因此,主线程仍被 React 占用,会继续处理下一个工作单元,也就是 button。
button 没有任何 child,这是我们第一次在树上触及到没有任何 child 的节点。因此,它没有创建任何工作单元。这样,React 就 complete 了这个工作单元。这时候,需要对比新的和旧的,看其是否有所改变。如果有所改变,需要做一个标记,来标识需要在 DOM 上做改变。button 并不需要做改变。
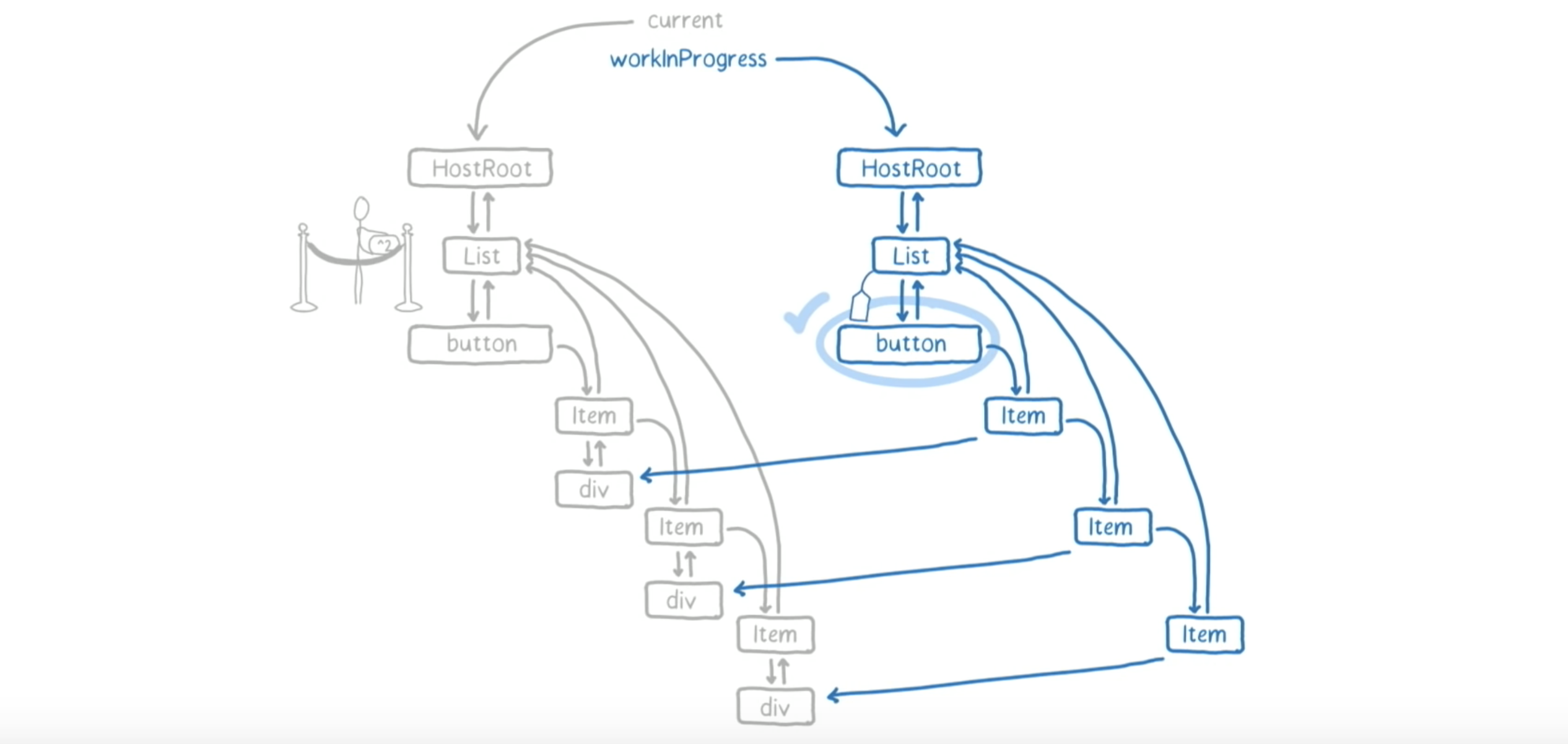
因为 button 没有 child,它返回 sibling 作为下一个工作单元。这样,下一个工作单元就是 Item,里面有一个数字 1。这时候,React 回去查看了一下 deadline,接着又回去继续工作。这遵循与 List 一样的模式。
但是,让我们假设在这个 Item 实例上有一个 shouldComponentUpdate 方法,定义了如果实例中数字的那个 prop 没有改变,则不需要更新。
也就是说,这个 Item 不需要打标识 DOM 需要更新的 tag。这样,这个 Item 也被 complete 了,并返回了它的 sibling 作为下一个工作单元。上去看看 deadline,然后再下来。
对下一个 Item 的处理是一样的,但这次,shouldComponentUpdate 返回的是 true。因此,它被打上了一个 tag,标记为发生了改变。接着,它的 div 被克隆,作为下一个工作单元被返回。
接着,检查 deadline。还有一点时间,所以,可以继续处理这个 div。这个 div 没有 child,因此我们可以 complete 它了。
我们比较了一下旧的和新的,发现 2 变成了 4。因为,我们需要在 DOM 上做改变,因此,我们在 div 上打上 tag。

同时,我们需要在 div 的父 fiber 上创建一个 change 列表,把 div 推入列表。需要把 div 推入 change 列表的原因是,它被打上了需要改变的 tag,以及它已经被 complete 了。
因为 div 没有任何 child,没有 sibling,也就不能返回下一个工作单元,所以,它的父 fiber,也就是 Item,就也被 complete 了。这样,Item 有 tag,也被 complete 了,那么,Item 也需要在它的父 fiber 上创建一个 change 列表,并将自己的 change 列表 merge 进去。这个 chagne 列表被称为 effect list。
这样,Item 把 div fiber 作为第一项推入父 fiber 的 effect list,接着,把自己作为第二项。
接着,Item 将自己的 sibling 作为下一个工作单元。此时,我们回去看看此时的 deadline。假设此时,我们已经将时间用尽了。所以,React 需要让主线程回去做其他的任务。
但是,React 当然还想完成自己的工作。因此,它利用 requestIdleCallback 告诉主线程,如果你做完手头的事了,回来和我把我的事做了。
主线程得以回去解决正在等待的回调。在我们的例子中,意味着主线程可以去做 layout 了。
在主线程结束工作后,它回到 React 这里,接着做之前的工作。
剩下的两个工作单元也以同样的方式被 complete,也就是打 tag,被加进 effect list。

这样,List 下所有的工作单元都已经被 complete 了。所以,List 也被 complete 了。
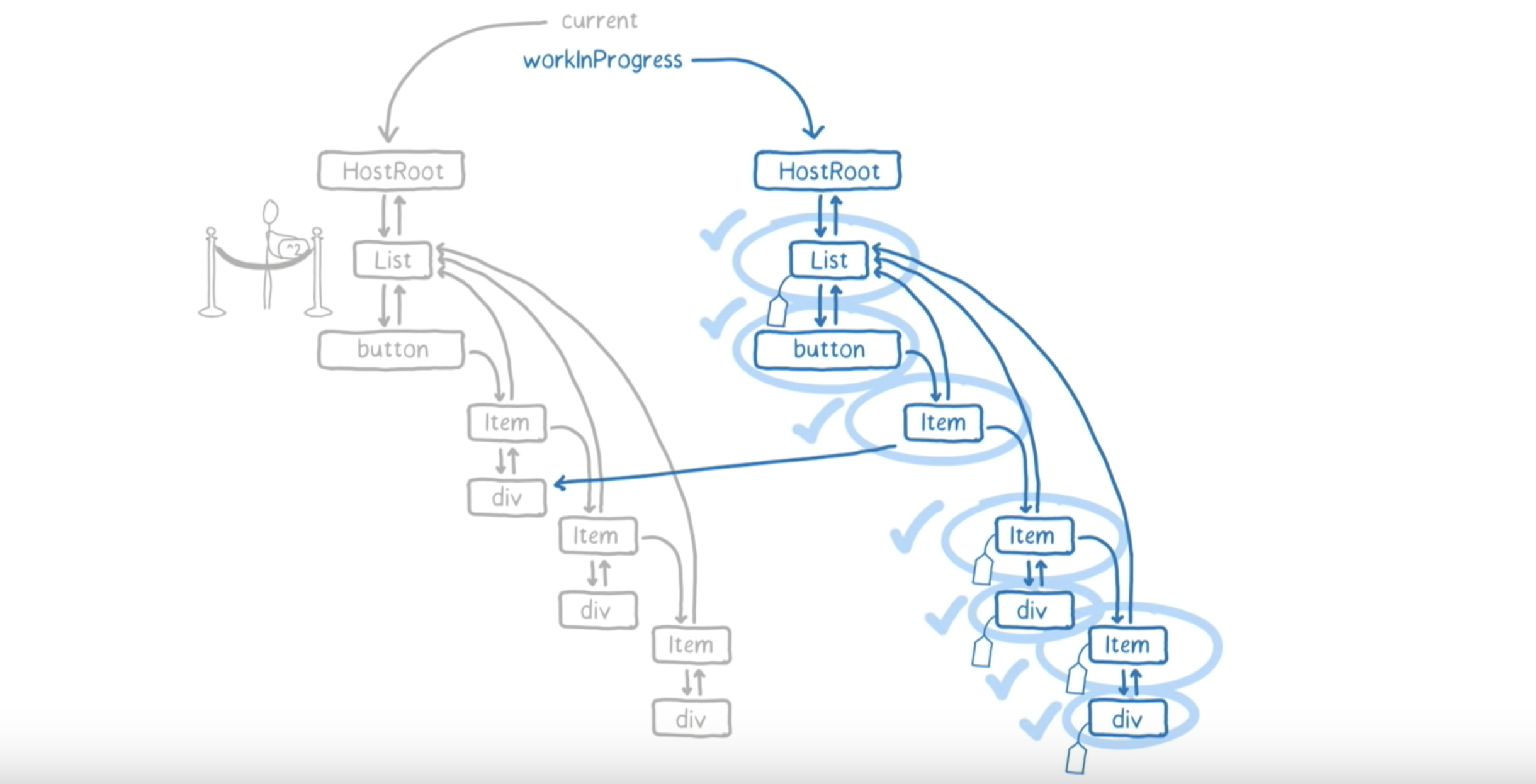
也就是说,List 把底下的 effect list 中的所有 fiber 都放进了其的父 fiber 的 effect list 中,然后把自己加在了末尾。

最终,在 List complete 之后,HostRoot 就也被 complete 了。接下来,React 就可以把这个 work-in-progress 树作为正在等待中的一个提交(pending commit)。
这样,第一阶段就结束了。我们完成了 work-in-progress 树,并找出了其中的更新。如下图:

接下来就是第二阶段了,真正地把这些改变提交(commit)到 DOM 上去。
React 会检查 deadline。如果还有时间,它会现在就提交。如果没有,它就会再次调用 requestIdleCallback,这样,主线程回来的第一件事就是提交。
让我们开始第二阶段。React 会遍历 effect list,然后从第一个 fiber 开始改变 DOM。也就是 div。这样,把 2 变成 4,接着移动到 Item,也就是 div 的父 fiber。在我们的例子中,Item 并没有改变,because we can’t using refs, but if we had a ref on here, that ref will be detached now and then it would be reattached later.
就这样,React 遍历 effect list,更新 DOM。这样,第一阶段计算的改变都被提交到了 DOM 树上。
也就是说,work-in-progress 树实际上是比当前的树更加更新版本的 app 的状态。因此,接下来,React 会把指向当前树的指针改为指向我们刚刚构建的这棵 work-in-progress 树。这样做有一个好处,就是让 React 可以复用之前的 object,它可以复用 work-in-progress 树里的东西。在下一次它需要构建 work-in-progress 树的时候,它也可以只是复制 key 和 value。这叫做双重缓存(double buffering),可以在内存分配和垃圾回收上节省时间。
所以现在,我们做完了这次提交。
React 会再次遍历 effect list 上的每一个 effect,然后再做一点事。它会执行剩下的生命周期钩子函数,更新 refs,处理 error boundaries。error boundaries 是 React 的一个新特性,它使你可以实际的处理 app 中的错误或是特定的部分。这使 React 更容易给你展示有用的错误信息,也意味着组件可以使用一个处理错误的方法自己处理自己的错误,
在每一个 effect 剩下的生命周期以及错误都已经被处理时,我们就结束了本次提交。
协调 React 更新与优先级更高的 React 更新的例子
上面的过程展示了 React 是如何对浏览器事件更加响应的。这是一个很好的特性,但就其本身而言,它并没有真正修复我们之前说的那个问题,也就是当 React 的提交被捕获时,可能会被堵在更大的 React 提交或者优先级更低的 React 更新后面。
为了修复这一点,我们需要再加一点东西,也就是优先级。
在 Fiber 调解器中,每一个更新都需要被分配一个优先级。

Synchronous 优先级的工作和现在的栈调解器很像,Task 优先级的工作需要在下一次事件循环之前(before the next tick of event loop)被处理,animation 使用 requestAnimationFrame 来安排发生的时间,因此会在下一帧被执行。High 优先级、Low 优先级以及 Offscreen 优先级,这三种都是被使用 requestIdleCallback 安排的。
为了页面看起来能够响应,High 优先级的工作应该尽快发生。Low 优先级的工作对小的延迟没有那么敏感,所以,如果是类似请求数据之类的操作,哪怕有额外的一二百毫秒的延迟,一般也不会被注意到。因此,Low 优先级可以被用在这种情况。Offscreen 优先级用于被隐藏或者现在还没有显示在屏幕中的东西,这类东西以防万一先渲染一下是很好,但不需要马上去做。
有了优先级的概念之后,我们想要的效果是,高优先级的工作能够跳到低优先级的前面,即使低优先级的工作已经开始了。
回到上面的例子,将使字体变大的按钮改为“紧急 React 更新”的按钮。用户点击按钮,就在主线程队列中塞进了一个 callback,但主线程不会立即处理它。直到 work loop 的 dealline 截止了,主线程才会来处理这个 callback。这个callback 调用了 setState。接着,React 会把这个更新加入更新的队列,但因为这是一个高优先级的更新,它跳到了我们已经在处理的低优先级更新的前面(也就是打断了第一阶段)。也就是说,在 React 再次开始工作时,它不会再从下一个工作单元开始,而是从 hostRoot 重新开始,并且差不多抛弃了所有它已经做过的工作。React 会遍历高优先级的更新,然后 commit,然后回头,再次从头开始低优先级更新。
这时,你可能会产生两个疑问。
一个是关于生命周期钩子的,一些生命周期钩子会在第一阶段,即协调阶段触发,而另一些生命周期钩子会在第二阶段,即提交阶段触发。也就是说,生命周期方法可能不会按你期望的顺序被触发。
在这次的例子中中,我们只演练不同优先级的更新。这是 componentWillUpdate 和 componentDidUpdate 是如何工作的。首先,一个低优先级的更新会触发 componentWillUpdate,接着,按钮被点击,高优先级的更新会触发 componentWillUpdate 和 componentDidUpdate,接着,低优先级的工作重新开始,触发 componentWillUpdate 和 componentDidUpdate。

在一些 app 中,你可能认为这两个生命周期钩子是对称的,也就是他们会以相同的顺序被成对地调用。但正如你所看到的,在使用 fiber 的情况下,并不一定是这样。因此,为了确保这不会让 app 出错,fiber 团队正在为此做一个优雅的更新路径。
另一件你可能想知道的事是,如果一大堆高优先级的更新插进队列的开头,那么低优先级的工作可能永远都不会发生。这被称为饥饿(starvation)。React 试图解决这种情况的一种方法是尽可能地复用工作。如果有一个低优先级的工作已经完成,而高优先级的工作没有接触到树的那部分,那么低优先级的工作就可以重用这部分。
fiber 团队正在积极研究其他解决方案来帮助缓解饥饿问题。
fiber 体系就是这样在短期内使 React app 变得更好的。fiber 允许更高优先级的更新跳到低优先级更新的前面,使更新在一起协调得更好。fiber 还使 UI 更加流畅且能够响应,这是靠将工作分解为更小的工作单元来做到的。工作单元可以被暂停,所以主线程可以去做其他需要做的任务。
顺便一提,这套体系有个名字,叫做 cooperative scheduling。你在其他类型的软件中也能看到这个,比如操作系统让不同 app 在一起工作得更好。